AI one-shot papers
On Twitter/X and LinkedIn, there has been a large discussion of the ability to “one-shot” policy evaluation, which David Yanagizawa-Drott has been pursuing in an interesting way: ape.socialcatalystlab.org
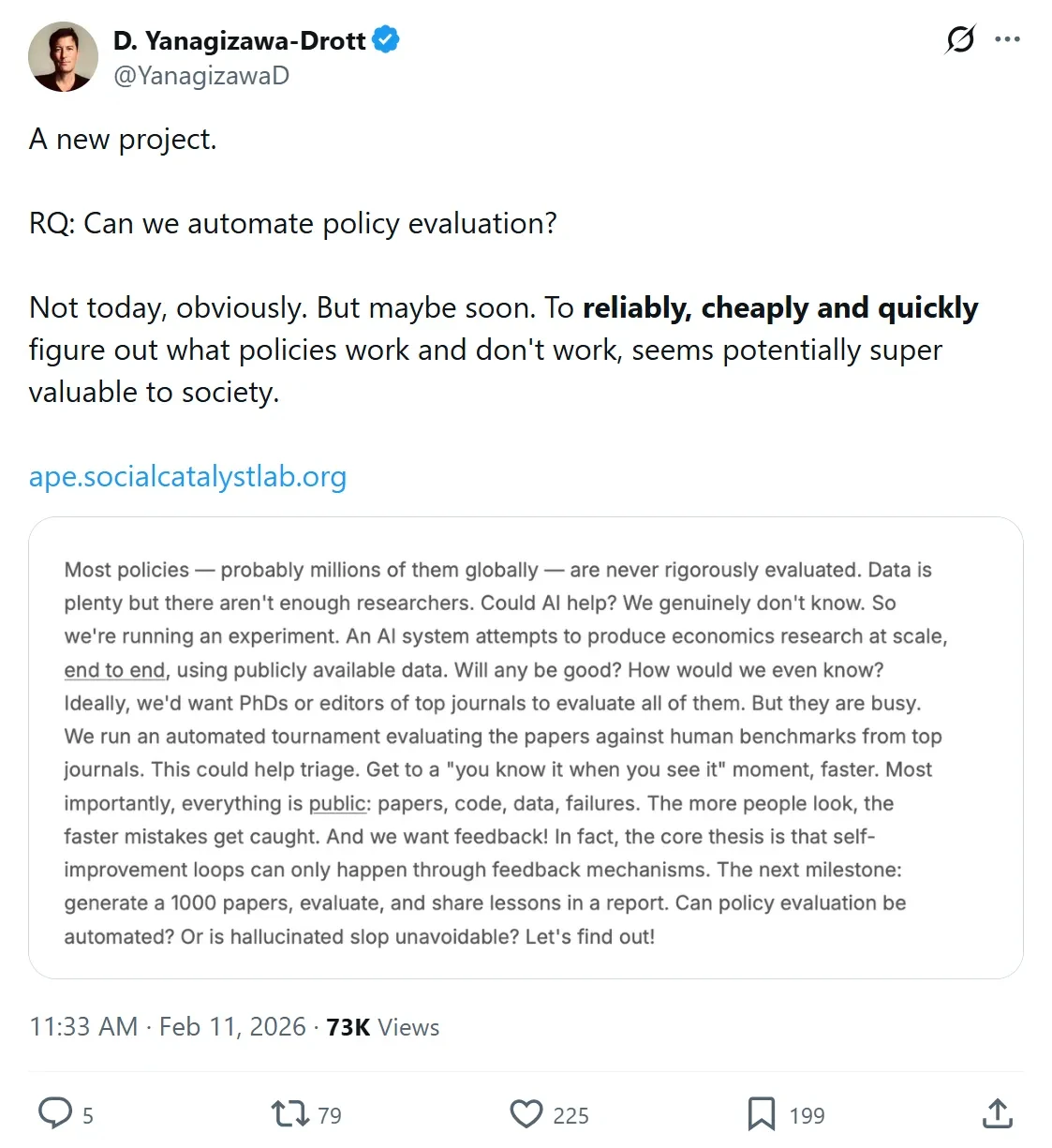
Here’s the punchline: automated AI procedures for empirical work are leaning even MORE on diff-in-diff. Why? It is very hard to do causal policy evaluations. Anyone who does empirical work knows this. The growth in diff-in-diff has partly been in response to limited exogenous variation.

My claim: AI “one-shotting” papers is going to heavily lean on methods that require a huge amount of taste, discretion, and care (diff-in-diff). Diff-in-diff is by far the easiest “plug-and-chug” empirical estimator (and has serious flaws, see my phd notes).
A scan through the APE social catalyst papers’ database confirms this. Of the 592 papers on APE’s AI papers Github site, 64.2% are self-reported diff-in-diff/ event study. 20% are RDD.
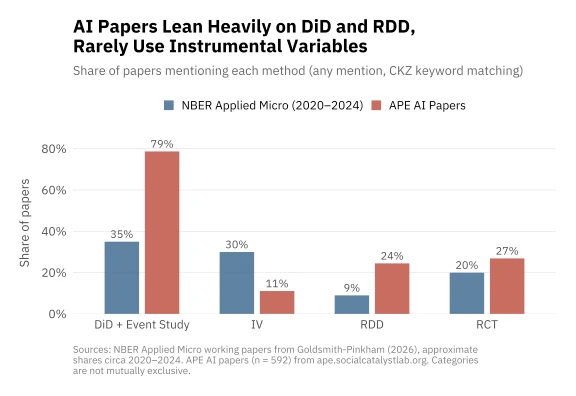
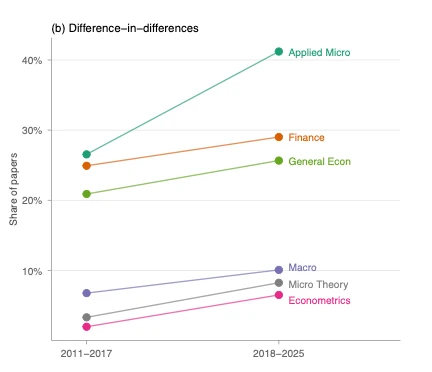
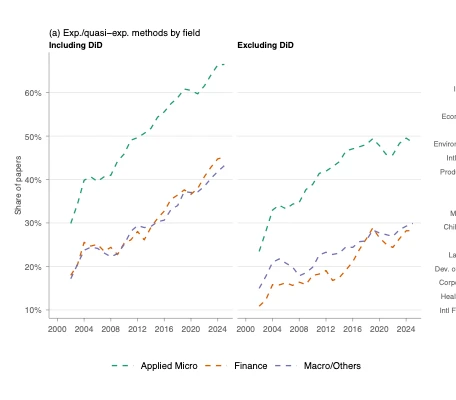
Contrast with NBER working papers in empirical micro: 35% mention diff-in-diff (higher recently), with 44% mentioning other forms of quasi-experimental variation. (from my own paper studying empirical research designs — new draft coming soon!), 35% of the papers mention diff-in-diff (higher recently), with 44% mentioning other forms of quasi-experimental variation. In published papers papers in the AEJ:AE and AEJ:Pol, the level is higher.
Rather than use the self-reported numbers, I tried to apply the same methodology to the APE papers that I used for my paper (thanks Claude Code, and APE’s very nicely accessible database). 73.8% of the AI papers mention DiD methods at least 3 times (way higher than the published or NBER papers). 21% of papers mention RDD.
Automated AI procedures for empirical work are leaning even MORE on diff-in-diff. If anything, my view is we are doing too much DiD nowadays for empirical applied causal work. To be clear, DiD can work great when done carefully. The question is whether an automated system can do ‘carefully.’
Originally posted as a thread on Bluesky.
