Research in the Time of AI
Academics are worried about AI replacing them and their work. I think we spend insufficient energy appreciating how much we can expand the frontier of research thanks to this new tool. To make this concrete, I find it useful to think about research as a pipeline of stages, from ideation through publication, and to ask where AI actually changes things.
Consider the following ontology for the stages of an academic research project in economics or finance.

In practice, all of these steps are iterative and reinforce each other. For example, results reshape the question, new data reshapes the analysis. Same for feedback after posting, etc.
Two anxieties about AI and research process
I want this ontology to give more structure to where I believe some of the debate is going on AI in academic research. A lot of the fears and concerns I hear discussed focus on two dimensions.
1. Slop
There’s going to be a whole bunch more stuff published, and some of this can just be “one-shot” from Step 1 to Step 8. This can be unpacked into multiple fears, some social, some private, and some both:
- People want to do more stuff and may not be as careful as they should be. Part of being an academic is devoting tremendous care and diligence to your work. There is an immense urge, once you have a tool that can help, to offload to that tool that may be a detriment to your work.
- Publications are important for academics’ careers and there will be strong private incentive to create more papers quickly to increase odds of tenure + raises + promotions. I think reputation concerns will alleviate some of this, but if all academics increase their output by just a bit, that is a huge set of new papers. For example, during the Covid period, there was a huge increase in papers (see the figure) as researchers were stuck at home working. This could possibly occur again, but to a much larger (and more permanent) degree.
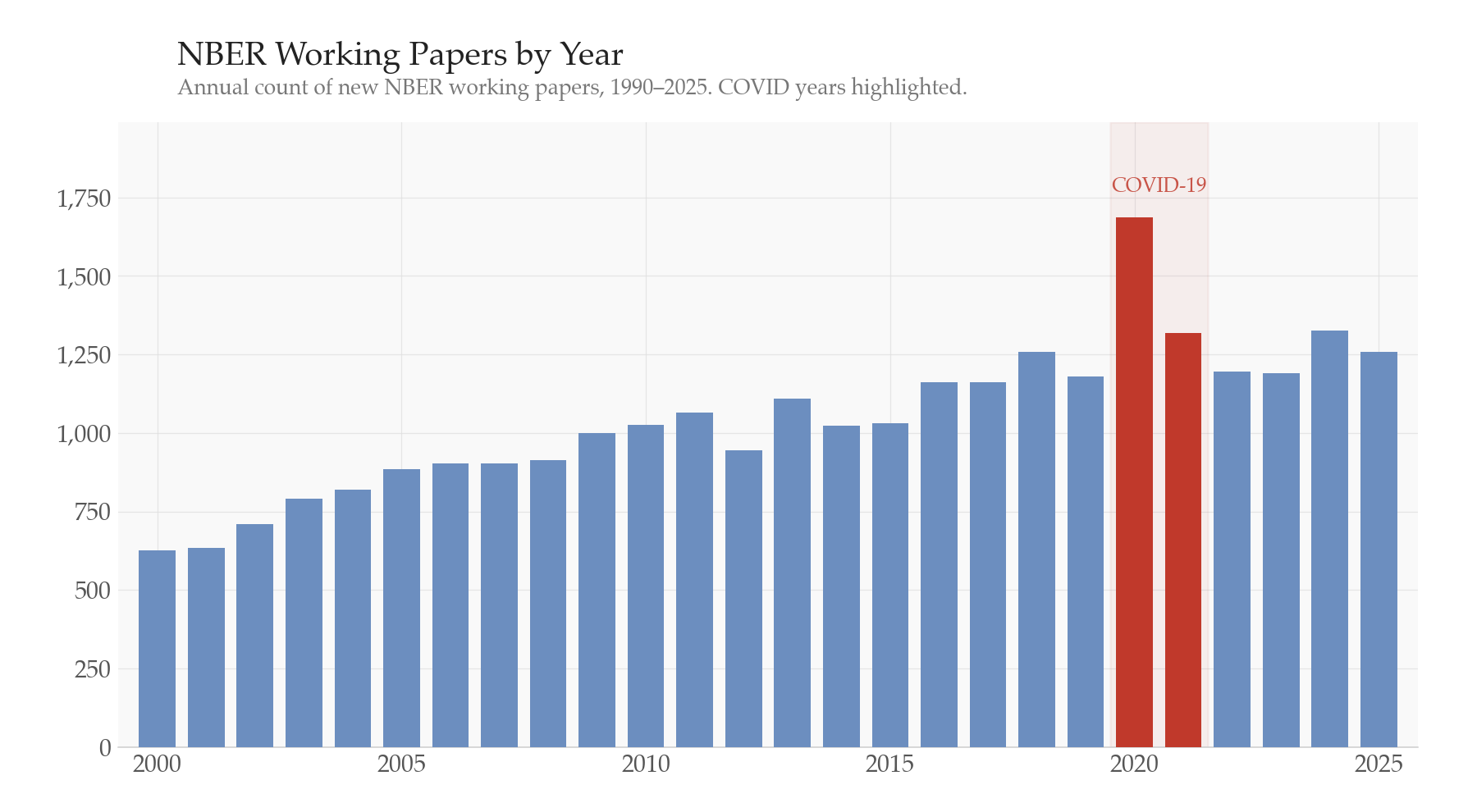
Much of this concern seems to be the view that AI can rapidly churn through all phases of the research process. The fact of the matter is that AI can churn through many parts of it. I completely agree that it does a good job — far better than most empirical researchers — at data assembly, analysis, and frankly even some writing. The figure below illustrates the fear: a researcher can potentially go from idea to posted paper in one shot, skipping the careful iteration that makes research good.

But the speed by which it can churn doesn’t mean that it’s going the right way for any given question. Often, the posing of the question or idea is typically the most important part (that is iterated on over and over in a paper). Of course, given a machine gun, you don’t have to hit on any given bullet – you can just spray and pray. It’s easy to imagine a world where researchers just try 1000 different paper ideas and see what sticks.
p-hacking by any other name?
A serious concern is that a focus on using AI for stage 4 and 5 will supercharge p-hacking. In fact, I have found Claude Code’s interest in presenting me a table of estimates where “X% of the regressions are significant” extremely worrying.
Nonetheless, p-hacking has always been an issue. And I think that the improvement in replication and open data will offset the ability to p-hack – in fact, I think that LLMs will give far stronger tools to researchers inclined to revisit old papers. Several people have independently suggested combing through old replication files to see if anything looks problematic.
The ability to quickly replicate and redo work suggests that p-hacked work will be caught much more quickly than before, offsetting the p-hacking concerns. We should be far more open to replication of work now as we can revisit old work much more costlessly.
2. Loss of job, rents, career
The academic anxiety is immense. Along many dimensions, academics are a profession that feels replaceable by AI. This is true both in teaching — we now have a chatbot that can respond to your every query! — and research — AI is one-shotting empirical research papers!
I get this. I do not have tenure. It is stressful how much this is changing. Software engineers are way more stressed out and I can see why! We are all living through interesting times, and Ph.D. students just went through one of the worst job markets in over a decade. We’re adding AI to a list of things to worry about along with funding cuts and everything else?
The key source of this anxiety, I believe, is that we’ve all invested a huge amount of time and energy into improving our ability to do different parts of this ontology. Some of us are amazing at programming, some at writing, and some at data access. Some are amazing at everything! The problem is that the advent of LLMs has significantly lowered the costs to doing these skills. Our human capital investments have significantly lower return now.
This is true for me — I’m a good (for my job) programmer, and I know a lot about econometrics. I promise you that it is far easier for someone to learn econometrics and do programming now than it used to be. You could now do a pretty good approximation of many hard things I spent the last 8 years learning post-Ph.D.
The pace at which we can move through the different stages is far faster than it ever has been. Costs and barriers are lower than ever before. That sucks if you invested to get over those barriers! And I don’t want to wave this away — for some people, especially those early in their careers who built a comparative advantage in execution skills like coding or data work, the depreciation is real and the adjustment is painful.
But I think it’s worth asking what this depreciation actually reveals about what was valuable in the first place. The skills that LLMs replicate are execution skills: writing code, cleaning data, implementing estimators, producing drafts. The skills they don’t replicate — at least not yet — are the ones that were always the hardest to teach and the hardest to learn: knowing which questions matter, developing taste for what makes a research design credible, understanding an institutional setting deeply enough to know where the data is lying to you, and iterating on a project until the argument actually works. Those skills have not depreciated. If anything, they’ve become more valuable, because the bottleneck has shifted toward them.
This is what I mean when I say that reducing costs has honed the question of what is good research. What is our goal as academics? Privately, it may feel like getting an AER publication, but ideally our goal is to further human knowledge, do better policy, and enrich our understanding of humanity. The people who will thrive are the ones who were always doing that — and the people who were coasting on execution barriers should be honest with themselves about it.
LLMs compress the research timeline
My view is that LLMs shorten the distance between and time with each stage, but do not railroad over the whole process.

Each phase still needs to be maximized and improved, and a good idea — a good project — is still crucial to expanding our knowledge.
Consider the ontology I presented above, but now with the gaps between the stages driven by the time and effort it takes to go through each stage. With LLMs, this is all compressed and shortened. We can now often move from ideation to actual data in an afternoon, rather than a week (or more). This does not mean we need to write every paper idea, but we can iterate far more to find the important and interesting papers. And perhaps we can find more venues to publish and post the work that is not quite up to the highest standards – not all papers can be evaluated on the same scale.
Why is it hard to write a good paper?
Or put another way, what makes good research hard? Most researchers do not love all their papers equally, and we have few papers that are perfect. This suggests that research is an imperfect and challenging process filled with fits and starts, groping and guessing in the darkness that is the frontier.
It’s hard to write a good paper because a paper is not about downloading a dataset, running a regression, or implementing an estimator. It is a carefully executed thought process that gives the reader (and the academy) an insight into how the economy and society works.
When you’re grasping in the dark, use the flashlight if you need it!
Having more tools to improve on this process is a boon. LLMs and AI technology can help in all stages:
- Ideation In ideation, you often can be headed in the right direction, prompting and guiding the context window towards an idea, much like reading through articles and using search engines. This can provoke an “aha!” moment, just like any other!
- Design & Feasibility The LLM is faster than any RA and can help you suss out what is possible (and can create new data faster than most programmers by webscraping and cleaning data efficiently). In addition, the code that AI can write makes the research far more replicable and usable.
- Data Assembly LLMs make structured datasets and validation much easier and lower the cost significantly.
- Core Analysis For applied researchers, the ability to implement state-of-the-art estimators is a real gain. The distance between econometrics theory and applied work can shrink rapidly. And from the theory side, the ability to embed empirical work in theoretical models (both micro and macro) is now far more accessible — I have had several colleagues talk about revisiting topics from grad school that were previously too costly to implement.
- Robustness & Extensions While I mentioned concerns about p-hacking, it is also valuable that robustness is not just the bastion of researchers with an army of RAs — LLMs flatten the playing field in a “complete” paper production.
- Writing If you use Claude, you are aware that LLMs can write very solid prose and technical analysis. I do not view LLMs as Hemingway, but I also think they can be much clearer than many academic writers. Researchers underappreciate the amount of guidance that you can give the LLM on your writing style. Of course, as with all writing, you need to edit and refine.
- Posting, Submission & Review Responding to R&Rs is far easier now. Often, you can more easily breakdown and understand the concerns brought by the referees, and structure a revision more quickly than before.
- Publication & Dissemination At a minimum, replication packages are much easier now. Visualizations to present your work are easier now. We all should be able to talk and present about our work!

This is just a small set of potential ways you can improve your abilities using LLM tools in research. Obviously, if you don’t feel like you need them, don’t use them! Sometimes it’s easier to walk at night using the stars and the moon for light than a flashlight.
We (academics) are dynamic, educated, thoughtful people. We can and should be incorporating these tools into our workflow and our teaching. We do ourselves and our students a disservice by not figuring out how to use them well. But the flashlight is just a flashlight — the hard part is still knowing where to walk.
